
アイキャッチ画像は「夏休みの宿題に苦労している男性」をGoogle GeminiにPromptをAI生成させてAMUSEにて画像生成させています。
Model:Dark Sushi Mix
Prompt:(masterpiece), (best quality), a young male student, close-up, struggling with summer homework, messy desk, a lot of notebooks, pencils, watercolor, desperate face, low angle, dusk
解像度:縦512×横768で生成しAMD XDNA Super Resolutionによって縦1024×横1536にアップスケール
AutomationでSeedを設定し、20枚を自動生成させたうち、イメージに合うものを選別しました。
かれこれ「AMUSE」を使い続けて半年以上が経過
AMUSEを使って半年以上が経過。YouTube上でAMDのCPUを使用したベンチマーク動画でAMUSEが使用されたり、それなりに画像生成AIソフトとして使用されているケースも増えてきているようです。
しかし、現状でも、日本語での情報があまりありません。いまだに公式から英語でのマニュアルすらない状況(いずれ出しますとは書いていますが・・・)。今でも各サイトを見ながら試行錯誤し、画像生成をしていました。
最近では専らExpert MODEで画像生成していますが、未だに設定したことがない項目がたくさん・・・。けど、無視していい項目もあるので、手軽に生成して楽しんでいます。
2025年5月3日のブログでExpert MODEのマニュアルを作成すると書くと宣言してから筆が進まず・・・。このまま放置するのはまずいので、Expert MODE編を書いていきます。
なお、全ての項目について説明すると膨大な量になるので、Text to Imege(言葉で画像生成する)のことに限定し、設定しておいた方がいいもの、作業が楽になる項目に絞って書いていきたいと思います。また、新たに判明したものについては、随時更新していきます。
今回(2025年8月10日)、記述するマニュアルについてですが、バージョン3.1.0をベースに作成しています。なので、将来的に操作方法、表示項目およびModel数の変更がありますので、ご注意ください。
【広告】現在は夏休み、秋の旅行、年末年始の旅行にJTBの旅行を
いつものおことわり
画像生成AIソフト「AMUSE」は、2025年8月10日現在、ベータ版であります。そのため、仕様変更は、かなり行われると思います。なお、今回使用しているパソコンは、ASUS製のVIVOBOOK S(M5406UA)で、ソフトの制作元(Tensor Stack社)が推奨する仕様ではないパソコンを使用して行っています。ただ、AMD社のブログでは、軽量のModelについては、使用しているパソコンでも画像生成できるようです。ですので、皆様がご使用の際には、以下の表を参考にして仕様に沿ったパソコンを使用するなど、自己責任でお願いします。
Models AMD Radeon™ グラフィックスカード AMD Ryzen™ AIプロセッサー SD 1.5 and LCM 少なくとも6GBのvRAMを搭載したほとんどのAMD Radeon™グラフィックスカード ほとんどの AMD ラップトップは 16GB の RAM を搭載しています。 SDXL, SDXL Lightning, SD3 Medium, SD 3.5 Medium AMD Radeon™ RX 9070 XT、Radeon 7900 XTX、Radeon 7900 XT、Radeon 7900 GRE、Radeon 7800 XT AMD Ryzen™ AI 300 シリーズ (32GB RAM 搭載)、Ryzen AI™ 395+ MAX シリーズ (32GB RAM 搭載)。(VGM = 16GB) FLUX.Schnell, SD 3.5 Large Turbo AMD Radeon™ RX 9070 XT、Radeon 7900 XTX、Radeon 7900 XT、Radeon 7900 GRE、Radeon 7800 XT AMD Ryzen™ AI MAX+ 395 シリーズ(64GB または 128GB RAM)。(VGM = 48GB) SD 3.5 Large, FLUX.Dev AMD Radeon™ PRO W7900 XT 48GB、Radeon™ PRO W7800 48GB https://www.amd.com/en/blogs/2025/experience-amd-optimized-models-and-video-diffusio.htmlより引用(一部和訳)
また、ネットでの情報、Google Geminiでの回答、私自身の知識と経験を元に記述しているため、誤った情報となってしまう可能性もあります。気づいた時点で修正していきたいと思っております。
【広告】最近流行のミニPC、お手頃価格から高性能まで揃っている「Minisforum」で!
上記の表にも対応したミニPCもございます。
Expert MODEの画面構成
最初にAMUSEを立ち上げるとEZ MODEになっています。

左下の最下段に、Expert MODEのボタンがありますので、そこをクリックするとExpert MODEになります。

これで、詳細な設定をして画像生成!といきたいところですが、EZ MODEで使用していたModelは「Fast」、「Balance」、「Quality」で指定したもので、内容がよくわからない3種類のModelをダウンロードしただけです。なので好みのModelをダウンロードしないと話が進みません。
そこで、どのようなModelがあるか先に選び、画像生成する前にダウンロードを済ませてしまいましょう。
【広告】当サイトはXServerのサーバーで運用しています。
まずは、Modelのダウンロード
画面の上部にメニューがあります。

ここで、Model Managerをクリックします。そうすると、Model一覧が出てきます。
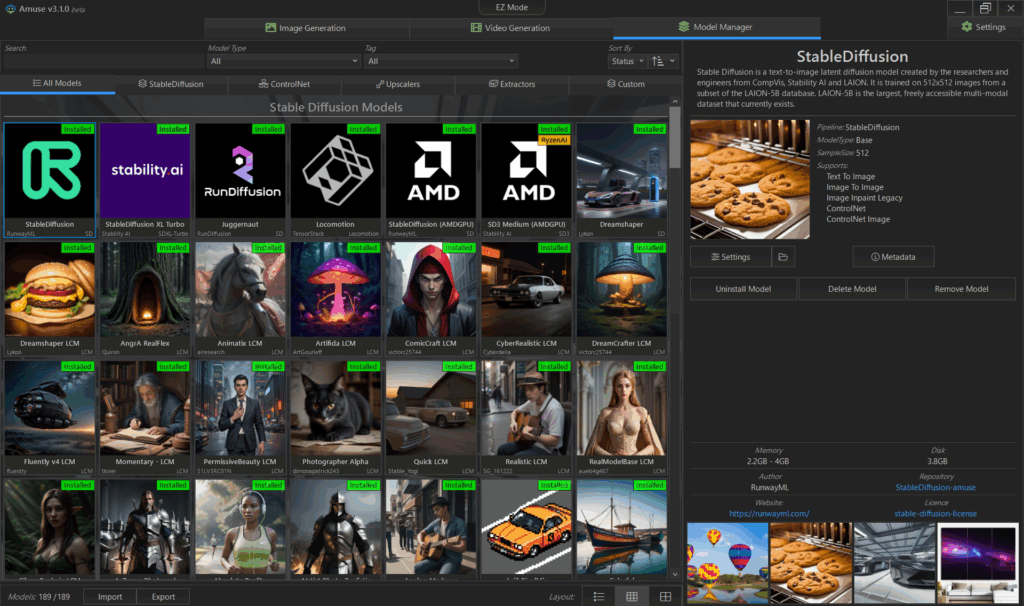
EZ MODEでは、「Fast」、「Balance」、「Quality」の3種類しか選べなかったのですが、Model Managerの一覧を見てみてると200弱のModelが出てきます。
選びたい放題のように見えますが、困ったことに、一覧ではランダムに出てきてしまい、何をModelを選んで良いか目移しすることがあるかもしれません。
前述の「いつものおことわり」に書いてある表にあるように、Modelによって使っているパソコンでは性能が足りず、せっかくダウンロードしたのに画像生成できないModelも含まれます。当然ですが、無理して使うと、AMUSE側からエラーメッセージが出たり、画像生成中にパソコンがフリーズします。そこでModelをダウンロードする際に、注意すべき点があります。その見極め方を説明します。
左側の画像をクリックすると右側にModelの詳細が出てきます。
ちなみにStable Diffusion XLを画像をクリックすると以下の情報が右側に出てきます。
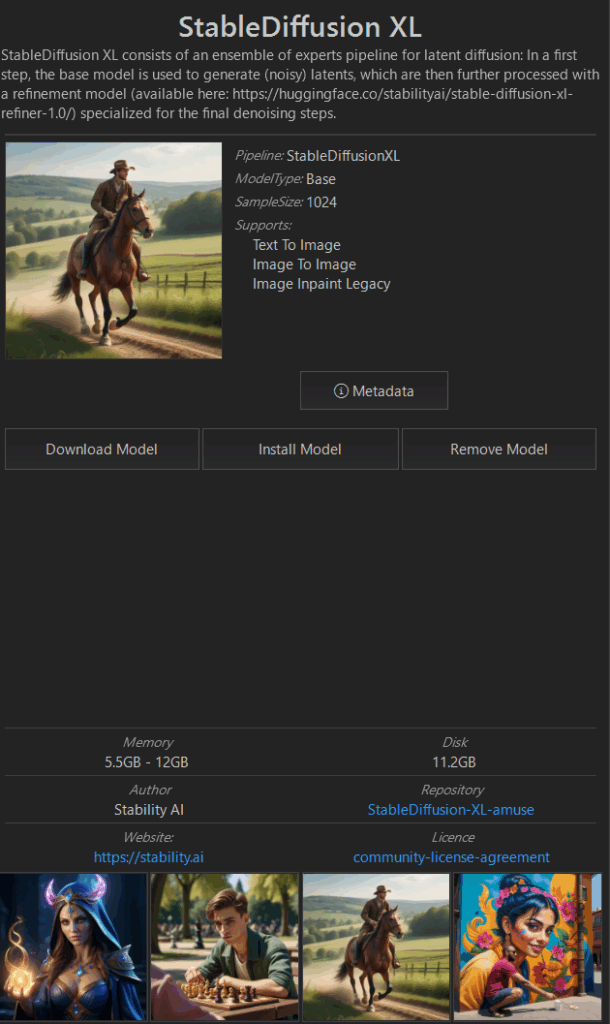
ここで注目していただきたいのは、Pipelineの項目です。このPipelineの項目で記載されている名称によって今お使いのパソコンでも無理なく画像生成することができるModelであるかどうか判断することができます(Pipelineの項目は、他のサイトでは、Stable Diffusionのベースモデルと表していることがあり、この後の記述でベースモデルと記述していることがあります。)。
1.Pipelineの項目がStable Diffusion若しくLatent Consistencyと記載されている場合(一覧の画像の右下にSD若しくはLCMと記載されている場合)
AMD社のブログや私が検証したことを踏まえると数年前にAMD製で揃えたグラフィックボードを搭載したパソコンであれば、画像生成をすることができると思います。基準の解像度は縦512×横512になり、メモリも調整すれば問題なく画像生成できます。ちなみにダウンロードするModelのデータ量はだいたい3GBになります。
この系統は、基本のStable DiffusionのModelはありますが、それ以外にも多くの種類があり、実写風の画像やアニメ調に特化した画像を生成することができます。
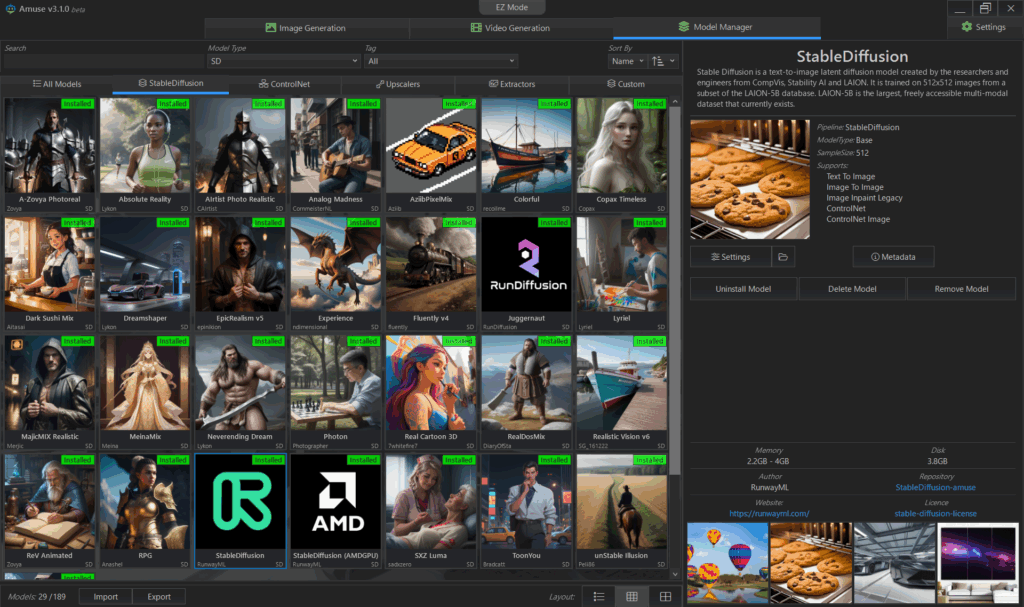
Model ManagerでのSDの一覧で、29のModelがあります。
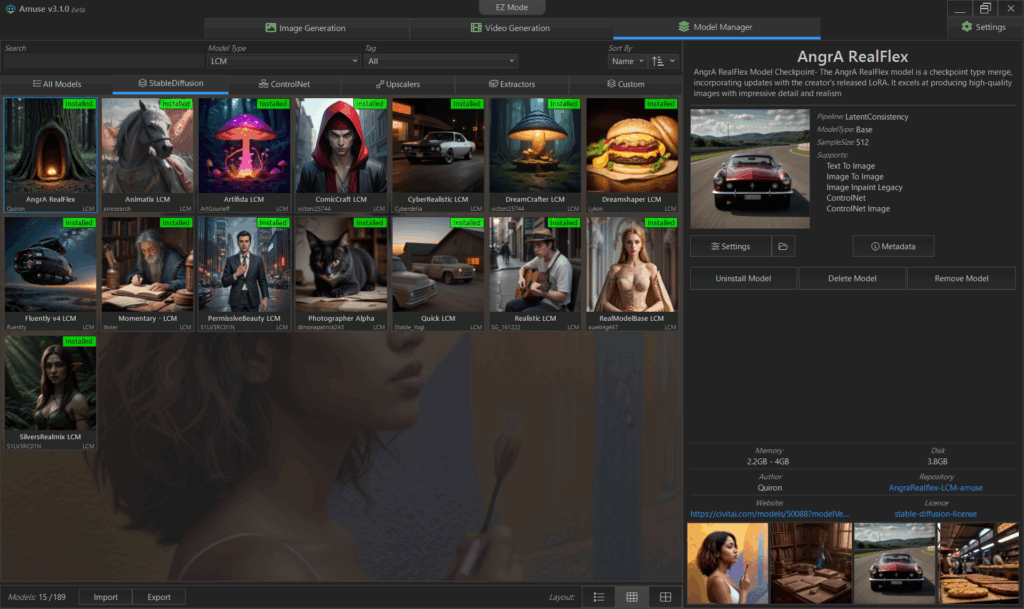
Model ManagerでのLCMの一覧で、15のModelがあります。
2.Pipelineの項目がStable DiffusionXLと記載されている場合(一覧の画像の右下にSDXL Lightning若しくはSDXL Tuboと記載されているものも含みます。)
画像生成される基準の解像度が縦1024×横1024となり、かなりメモリを消費します(ただしSDXL Tuboは縦512×横512になります。)。その理由は、学習モデルが前項で記述しているデータ量が3倍以上の11GBになります。なので私が検証しているパソコンでは、画像生成できるかフリーズするかギリギリの範囲内になります。ただ、データ量が多いことによって生成される画像がバリエーションが増えていきます。
この系統も、基本のStable Diffusion XLやStable Diffusion XL Tuboがありますが、それ以外にも多くの種類があり、実写風の画像やアニメ調に特化した画像を生成することができます。
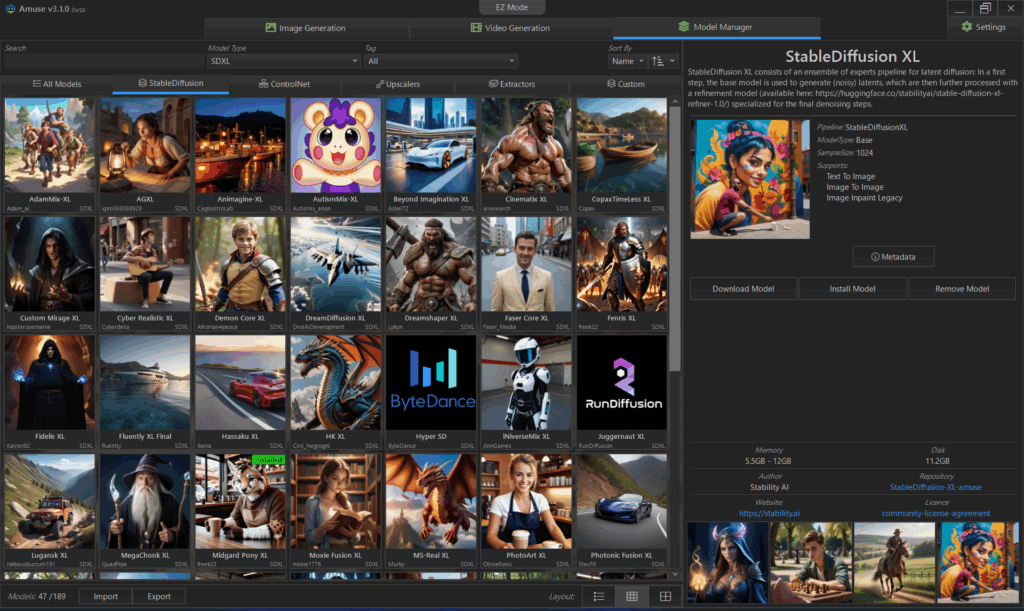
Model ManagerでSDXLの一覧で、47のModelがあります。このほかSDXL Lightningは11のModel、SDXL Tuboは4つのModelがあります。
3.Pipelineの項目がStable Diffusion 3若しくはFLUXと記載されている場合
すいません。手持ちのパソコンでは仕様以上のグラフィックボード等が無いので、検証することができません(後日検証する機会があれば試してみます、期待薄ですが・・・)。
手始めに画像生成したい場合は、Pipelineの項目がStable Diffusion若しくLatent ConsistencyのModelをご使用していただければと思います。
好みのModelが見つかった場合は、中段の「Download Model」をクリックすれば、ダウンロードが開始されます。複数個ダウンロードしたい場合は、ダウンロード中でも、他のModelをダウンロードすることができます。但し、Pipelineの項目がStable Diffusion若しくLatent Consistencyの軽量級のModelでも3GBあり、Text to Imegeに対応しているモデル数は129もあるので、ディスク容量に気をつけてダウンロードしてください。(ディスクに余裕がない限り、気に入ったModelで無ければ、削除してください。色々ダウンロードした結果、ディスクの容量が10%を切り余裕がなくなってしまって焦りました。2025年8月12日追記)
【広告】そろそろお疲れのところでしょう。国内旅館のご予約は、「一休.com」で!
画像生成 その1 Modelの選択
好みのModelをダウンロードしたら、が画面の上部にメニューのImage Generationを選択します。
次に、左上部にある、Model Selectorがあります。
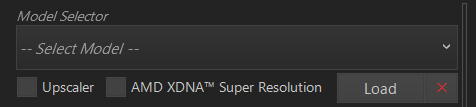
この項目にある、–Select Model–の∨をクリックし、使用したいModelを選択します。
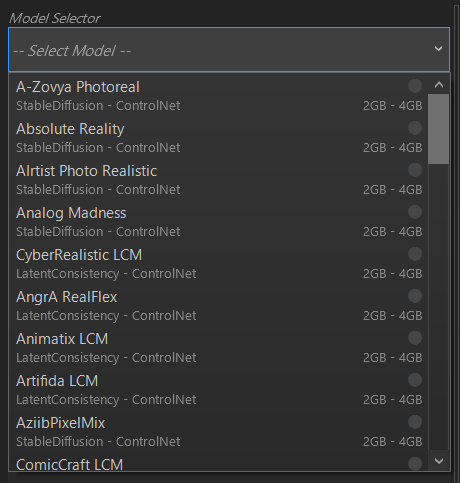
選択後、「Load」ボタンをクリックすると、Modelを読み込みます。その後、問題なければ「Ready!」と表示され、プロンプト等の入力ができるようになります。
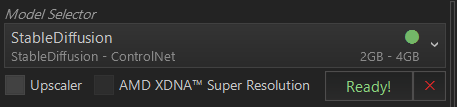
Model Selectorの下にある、「UpScaler」の項目があります。Model ManagerからUpScale Modelsの中から選んだ場合、ダウンロードした項目が以下の通り表示されます。お好みのUpScalerを選択することができます。が、私が使用しているノートパソコンでは選択することができませんでした(後日、別のパソコンで検証してみます。)。(なぜ、この項目を気にしていなかったのは、この下に記述したとおり、AMD XDNA Super Resolutionの機能が使えたので、気にしていませんでした。ふと思って、いつも使っているのと別のデスクトップパソコンで試した際に、念のためUpScalerのModelをダウンロードしたところ、選択することができることが判明しました。2025年8月12日赤字分、下の画像を含め追記、削除)
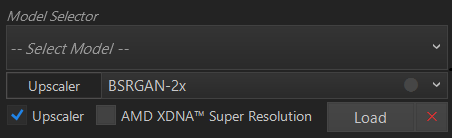
AMD XDNA Super Resolutionについては、AMD製のNPU内蔵のCPU搭載(Ryzen AI300 シリーズと Ryzen8000 シリーズの一部など)のパソコンであればRyzen AIを利用して、解像度を上げてくれる機能です。対応CPUであれば選択項目が出てきます。選択した場合、Optionで設定した縦横サイズを倍にして画像生成してくれます。私が使用しているノートパソコンではこちらの機能が使えるので、選択することができました。(2025年8月13日赤字部分、下記画像追記)
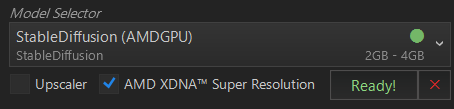
この項目については、別の記事で検証しています。(2025年8月13日赤字部分追記)
画像生成 その2 プロンプトとネガティブプロンプト
画像生成するためには、何を画像にしたいのか命令する必要があります。それを命令するために必要な単語をプロンプト(Prompt)に入力します。日本語化には対応せず、英語のみの対応になります。
生成した画像をインターネット上に出す場合や職場で使う場合、法的上、宗教的上に不適切なものや、画像上おかしな点を排除したい場合が生じます。その場合にはネガティブプロンプト(Negative Prompt)に記述する必要があります。
ネガティブプロンプトについては、ベースモデルがSDXL Tuboの場合やLCMを設定してGuidance Scale(後述参照)を1.0に設定している場合は、項目が省略され、記述することができないようです。
プロンプト、ネガティブプロンプトの詳しい説明をここで記述すると膨大になるので省きますが、詳しい説明を紹介したサイトがたくさんございます。「Stable Diffusion プロンプト」と検索していただくと作成したい人物像、背景、風景、画角などのイメージしたいプロンプトを探すことができます。ここでしっかり命令しないとイメージと違うものが生成されてしまうことがあります。
ただ、曖昧に命令した場合でもイメージしていたものと違う新たな画像と出会えることもあるので、そこは個人ごとに楽しんでいただければと思います。
画像生成 その3 オプション(Options)
この項目は、画像生成で必要な基本的な設定を行う項目になります。
ただ、あまり気にしなくても画像生成できる項目もあるので、その点も含めて解説します。
Scheduler
新たにSchedulerに関する記事を新たに書きました。(2025年8月29日追記)
Schedulerを説明すると長くなりそうなので、GoogleのGeminiに聞いてみたところ、
AMUSEにおける**Scheduler(スケジューラー)**は、Stable Diffusionの画像生成プロセスにおいて、ノイズを除去して最終的な画像を生成するためのアルゴリズムです。Stable Diffusionでは、ランダムなノイズから、ステップごとに少しずつノイズを取り除き、画像を生成していく「拡散モデル」という手法が使われます。スケジューラーは、このノイズ除去の「やり方」を定義する重要な要素です。
とのことです。
Stable Diffusion Web UIでは、Sampling methodと記述されている項目になるそうで、ネット上ではサンプラー(Sampler)で検索した方が詳しく解説されています。
色々、項目があるのですが、ここは、初期値で問題なく、画像生成することができます。
ただ、Schedulerには個性があるようなので、画像の仕上がりに若干の差があるようです。
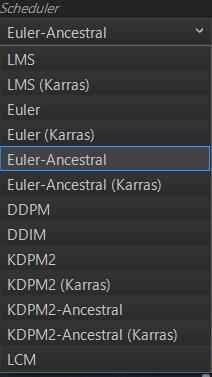
ModelをStable Diffusion(AMD GPU)を選択した際のSchedulerの一覧
この違いについても、Google Geminiに聞いてみたところ、
代表的なスケジューラーの種類
AMUSEを含め、多くのStable Diffusionのツールで利用できる代表的なスケジューラーには、以下のようなものがあります。
- Euler/Euler Ancestral: シンプルで高速なスケジューラー。Euler Ancestralは、ステップごとにノイズを追加するため、生成するたびにわずかに異なる画像が生まれます。
- DPM-Solver (DPM++ Karrasなど): 少ないステップ数で高品質な画像を生成できることで人気です。特にDPM++ 2M Karrasは、速度と品質のバランスが優れていると評価されています。
- DDIM: 初期から使われているスケジューラーで、安定した結果が得られますが、他のスケジューラーに比べて多くのステップ数が必要になる傾向があります。
- LCM (Latent Consistency Models): 非常に少ないステップ数(通常は4〜8ステップ程度)で画像を生成できるため、リアルタイムに近い高速な生成に適しています。
とのことです。
Enable Live Update

特に選択しなくてもよいようです(これを選択しても、メリットがわからないので、後日検証してみます。)。
Seed
シード値を設定する項目です。基本的には初期値のまま「0」(ゼロ)で大丈夫です。
初期値のままで画像生成したときに、シート値が出てきます。
このシード値は、同じModel、同じPrompt、同じScheduler、同じシード値に設定していれば、同じ画像を生成してくれます。
そのことを利用して、シード値を固定し、表情や髪型に関するPromptを追加することによって、全体の構成をあまり変えずに表情や髪型だけを変更することができるようです。

上記のマーク(New Seed)は、新たにシード値を出してくれます。
上記のマーク(Random Seeds)は、シード値を初期化してくれます。
Resolution(解像度調整)
Resolutionは画像生成したいサイズ(解像度)を調整する項目です。
∨のボタンをクリックすると、サイズの一覧が出てきます。
ここで、大まかなサイズ調整することができます。
また、右の

ボタンを押すと、以下の画像の通り、縦横のサイズを自由に選択することができます。
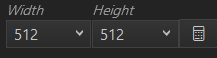
なお、サイズを大きくするとメモリ消費も大きくなるので、ご自身のパソコンの性能によって調整してください。
Steps
画像生成するために必要なステップ数を調整する項目です。

Schedulerの項目でも書きましたが、AMUSEに限らず、Stable Diffusionではランダムなノイズから、ステップごとに少しずつノイズを取り除き、画像を生成していく「拡散モデル」という手法が使われます。
そのため、思い通りな画像を生成する場合、ステップ数が重要になっていきます。
ただ、ステップ数が多ければ良いわけではなく、処理時間が長くなるだけの結果になります。1枚程度であれば、多少の処理時間が延びたくらいですが、複数枚を自動生成させたときにその差が大きく出てきます。
各ベースモデルによって適切なステップ数があり、ネットでも推奨しているステップ数の記述もあります。また、Modelの公式でも推奨するステップ数が記載されているものもあります。ただ、私自身の経験則でいえば、以下の通りとなります(もう少し少ないステップ数でも画像生成することができますが、思い通りの画像ができませんでした。)。
- Latent Consistency(LCM) 20ステップ程度
- Stable Diffusion(SD1.5) 30ステップ程度
- Stable DiffusionXL(SDXL)50~60ステップ程度
- SDXL Lightning 20ステップ程度
- SDXL Turbo 4ステップ程度でもよさそうな画像が生成されますが、10ステップ程度(ステップ数を増やすと画風が大分変わるようなので、要検証)
Guidance Scale
この項目は、私自身は、基本的に初期値のままで使用しています。
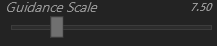
念のため、Google Geminiに聞いたところ、
AMUSEにおける**Guidance Scale(ガイダンススケール)**は、画像生成AIのStable Diffusionで非常に重要な役割を果たす設定項目です。他の画像生成AIでは「CFG Scale (Classifier-Free Guidance Scale)」とも呼ばれます。
Guidance Scaleは、入力したプロンプトにどれだけ忠実に画像を生成するかを制御するパラメーターです。この値が高いほど、AIはプロンプトの指示を厳密に守ろうとします。
とのことです。
この数字を大きくすればするほど、プロンプトに忠実な画像を生成してもらえますが、その引き換えに処理時間がかかります。
Memory Mode
画像生成AIソフトは基本的にメモリを多く消費します。それをどの程度使用するかこの項目で大まかなメモリ消費の調整を行うことができます。

通常は初期値(Auto Detect)で大丈夫ですが、私のノートパソコンではStable DiffusionXLクラスのベースモデルを使用するとエラーメッセージが出たり、フリーズしてしまうことがあります。なお、パソコンの構成により、メモリカウントの仕方が異なるようです。上記画像は、使用しているノートパソコンでBIOSでの専用メモリ割り当て2GBと共用メモリ割り当て7GBを足した9GBがメモリ総量9GBとカウントしています。念のため、グラフィックボードを搭載したデスクトップパソコンで試したところ、グラフィックボード搭載のメモリ8GBと総量としてカウントしています。(2025年8月19日赤字追記)
そのときは、∨をクリックして、Minimumに調整して、画像生成しています。
また、Customを選択すると、使用しない機能を選択することにより、メモリ消費を調整することができます。
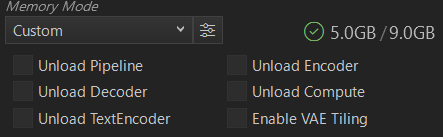
また、どれぐらいメモリを使用するか、この項目の右にある数字やマークで問題なく画像生成するか参考にすることができます。マークには以下の説明があります。
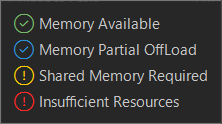
Memory Available 使用可能メモリ(問題なく生成できます。)
Memory Partial Offload メモリ部分退避(共有メモリなどを利用すれば生成できます。)
Shared Memory Required 必要な共有メモリ(確実に共有メモリ若しくはSSDなどを利用します。エラーが出る場合があります。)
Insufficient Resources リソース不足(確実に生成不可です。)
緑色であれば、問題なく画像生成してくれます。赤色の場合は、諦めましょう。(2025年8月19日赤字追記、削除)
【広告】旅の予約は、楽天トラベルへ!楽天ポイントも貯まります!

画像生成 その4 Generate
上記の項目に、入力、設定できたら、後は下部にあるGenerateボタンを押すことにより、画像生成が始まります。

画像生成を中止したい場合は、Cancelボタンを押せば中止されます。
エラーメッセージ等が出なければ、画面右側に生成された画像が表示されます。
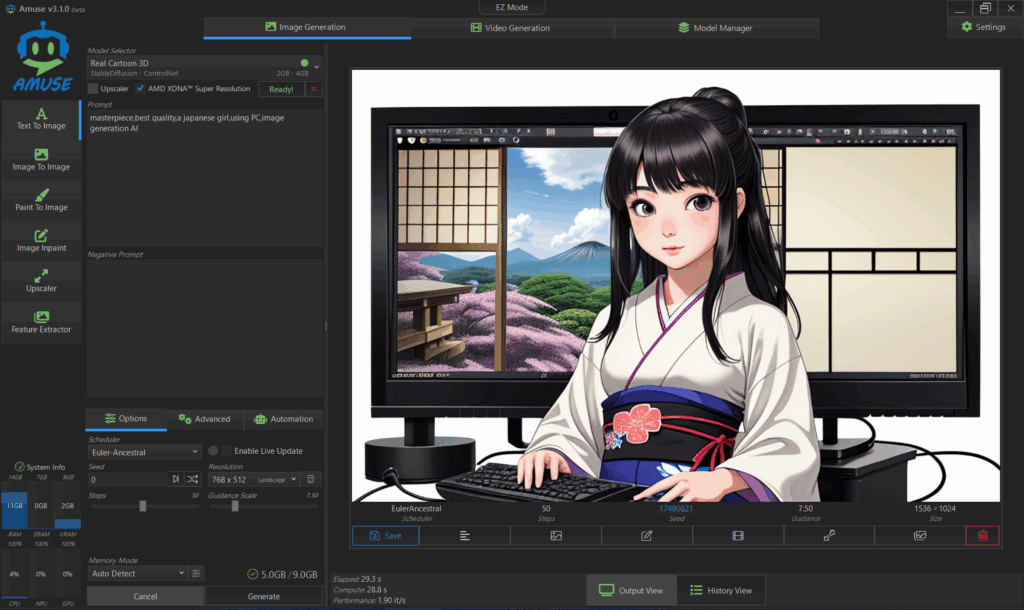
画像生成後の画面の一例
Model:Dark Sushi Mix
Prompt:masterpiece,best quality,a japanese girl,using PC,image generation AI
Steps:50
Guidance Scale:7.50
画像生成後、Generateボタンを押せば、また雰囲気が変わった画像(シード値が変わった画像)が生成されます。
画像生成 その5 Advanced
この項目については、調整していません。今後勉強します。
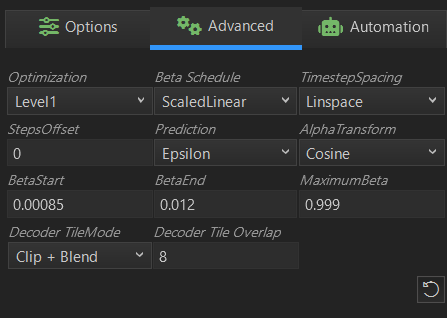
上記画像はStable DiffusionをロードしたときのAdvancedの設定項目と初期値です。
画像生成 その6 Automation(画像生成の自動化)
この項目は、自動で複数枚の画像生成をしたり、Modelがどのように画像生成してくれるかステップごとに画像生成してくれる項目です。画像生成において、いろんな画像を見比べてみたい場合には必要な項目になります。
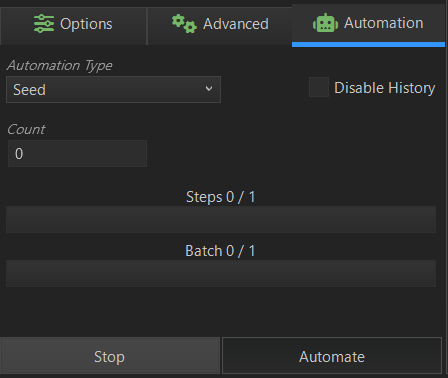
Automation Typeの項目の∨をクリックすると、以下の選択項目が出ます。
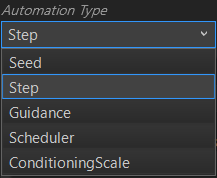
ここでは、「Seed」と「Step」について説明します(他の項目については、色々試した見たのですが、よくわからないので後日検証してみます)。
Seed
Automation Typeの項目をSeedに選択すると以下のようになります。
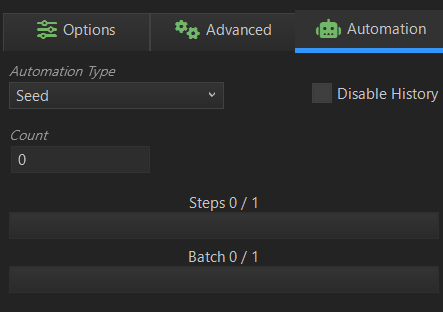
Disable Historyの項目にチェックを入れると出力された画像が履歴として残りません。なので、複数枚自動生成して、後から探してみたいときは、チェックを外してください(次のステップでも同様です。)。
Countの項目は、出力したい枚数を設定します。
設定後、画像生成させる場合は、Automateボタンをクリックします。

画像生成を途中で中止したい場合は、Stopボタンをクリックしてください。
指定した枚数で自動的に停止し、シート値を変えた画像が指定枚数出力されます。
ただ、仕様なのかバグなのかわかりませんが、起動直後の場合、指定した枚数ではなく、1枚のみ生成されるのです。また、数字変更後しても、前に入力した数字の枚数しか生成されないときもあります。なぜでしょう・・・(次のStepも同様です。)
Step
この項目は、あまり使わないと思うのですが、使用しているModelがどの程度のステップ数でイメージ通りの画像ができるか検証するツールみたいな項目です。
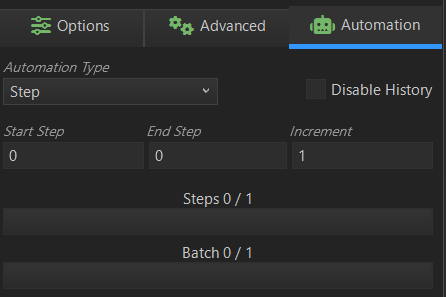
Start Stepには、例えば5ステップ目を出力したい場合は、5と入力します。なお、0(ゼロ)のままだとエラーメッセージが出ます。
End Stepには、目標としているステップ数を入力します。
Incrementには、例えば1ステップずつに出力したい場合は、5ステップ毎に出力したい場合は、5と入力します。
設定後、画像生成させる場合は、Automateボタンをクリックします。
上記をまとめると、Start Stepを5、End Stepを50、Incrementを5と入力した場合、最初に5ステップ目の画像が出力され、その後、10,15,20ステップの画像が出力されていき、最終的に50ステップの画像が出力され、計10枚出力されます。この出力結果を見比べて、どのステップ数までであれば、むやみにステップ数を増やさずに望みの画像が出力されるか検証できます。
自動化して作成した出力結果を見比べたい場合や生成された画像を保存する場合
出力された画像は、AMUSE起動中に作成したものであれば、過去の履歴を見ることができます。
過去の履歴を見たい場合は、出力された画像の下部にHistory Viewボタンをクリックすれば、一覧で表示することができます。

また、元に戻りたい場合は、Output Viewボタンで戻ります。
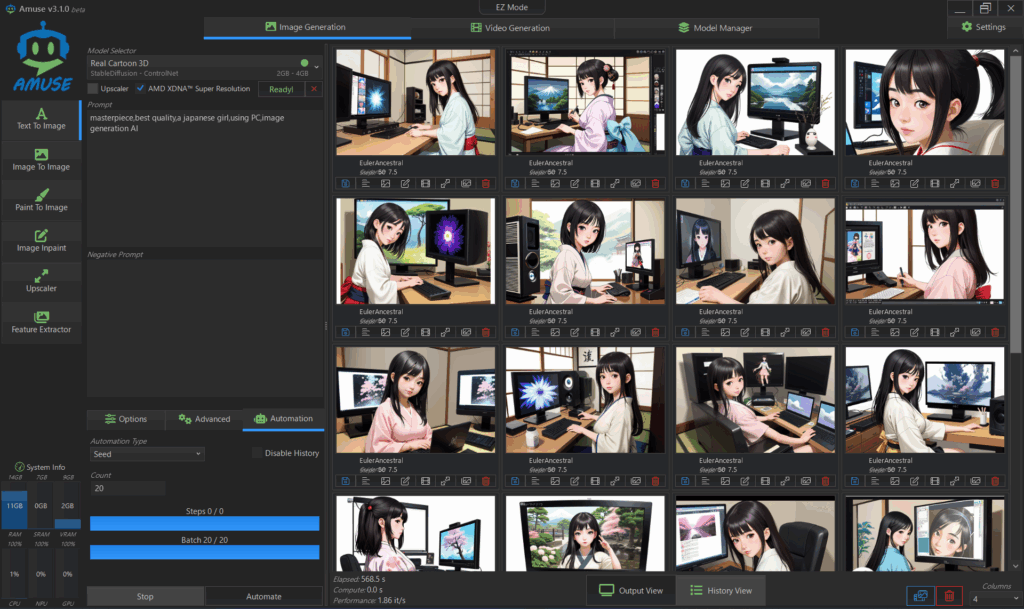
画像生成後の履歴画面の一例で、全て同じプロンプトで作成したものです。
Model:Dark Sushi Mix
Prompt:masterpiece,best quality,a japanese girl,using PC,image generation AI
Steps:50
Guidance Scale:7.50
なお、出力された画像はそのままでは保存されず、起動後改めて見ることはできませんので、ご注意ください。
生成された画像を保存したい場合は、Output Viewの画面であれば、出力された画像の左下にあるSaveボタン(青いフロッピーディスクの形のボタン)をクリックして、希望のフォルダに保存してください。また、History Viewの画面であれば、出力された画像の左下にある青いフロッピーディスクの形のボタンをクリックすれば同様に保存することができます。
終わりに
書こうと思ったのが5月で、その後、書こうと思ってもなかなか筆が進まず、実際に書き始めたのが8月、これを書くのに延べ4日。まるで夏休みの自由研究を書いているみたいでした。なので、アイキャッチ画像はそれをイメージして生成させました。
前回のEZ MODE編に比べ、全てを網羅したものではないにしろ、分量が倍になってしまいました・・・
改めて書いてみると今までわからなかった点などの発見があり、今までの不明点が解決され、文章をまとめることができたと思っております。
8月10日に一応書き上げましたが、今後も修正していく点があれば修正していきます。大きな加筆・修正があれば、その旨を記述していきます。落ち着いたら、しれっと広告を入れていますが、その点は突っ込まないでください。
【広告】いろんなものが最短で翌日に届く。是非アマゾンへ

終わりに その2 生成した結果、磨りガラス(スモーク)がかかったような画像が生成される場合(2025年8月11日追記)
無料で使えて、ソフト1つインストールするだけの画像生成AIソフトの中ではAMUSEが一番手軽なものだと思っております。とても便利です。
但し、いわゆる有志グループが作成されているものではなく、ニュージーランドの企業Tensor Stack社が作成しており、CPU、GPUなどの半導体を製造している有名企業のAMD社が協力しているソフトです。そのこともあって、各企業はコンプライアンスの遵守が必須となります。また、世界各国でダウンロードできることになると、各国の風習、習慣、倫理の差異があれど、それに反する行為は、企業イメージの低下に結びつきます。
そのため、AMUSE自体に禁止されているプロンプトがいくつかあり、それが含まれている場合は、エラーメッセージが表示されることがあります。
また、ソフト側で不適切と判断した場合や、Modelでは表現できない画像と判断した場合は磨りガラス(スモーク)がかかった画像が生成されます。これは、選択したModelや設定したPromptによって全滅であったり、歩留まりが良かったり悪かったりと一律に決まっているものではないようです(ある意味運次第)。
無料で使えるソフトでもあるので、その点、ご留意いただければと思います。
【広告】楽天ポイントをためている方は、当然、楽天市場へ


